47M参数打赢7B:语音判停模型TurnSense开源
你的语音Agent又抢话了。
用户说"我想订那个……就是上次去过的那家……",话还没说完,AI已经兴冲冲回了一句"好的,请问您想订什么?"
"帮我查一下那个……"——一秒的停顿,AI拿着半句话就开始生成回复了。
更荒谬的是:用户咳嗽了一声,AI开始正经回答一个不存在的问题。用户清了下嗓子,AI说"好的,我来帮您处理"。旁边有人关了一下门,AI又开口了。
这些问题的根源不是你的大模型不够聪明,而是系统根本不知道什么时候该接话——更准确地说,系统分不清哪些声音是"话",哪些根本不是。
现有方案为什么不行
目前主流语音Agent的判停逻辑是VAD + 静音阈值——检测到N毫秒没声音,就认为用户说完了。但这个方案有两个致命问题。
第一,它分不清停顿和说完。 人说话会思考、会犹豫,1秒的沉默不代表一句话结束。
第二,它分不清人声和噪声。 VAD检测的是"有没有声音活动",而不是"有没有语言意图"。咳嗽、叹气、清嗓子、甚至环境中的碰撞声,都可能被VAD标记为语音活动,经过ASR后产生幻觉文本,触发大模型生成一个莫名其妙的回复。在真实部署环境中,这类噪声误触发的频率远比你想象的高——特别是车载、开放办公、户外等场景。
行业开始转向模型判停——用深度学习模型判断用户是否说完。但现有方案存在一个三角困境:精度、成本、速度,最多满足两个。
7B参数的方案精度不错、延迟也低,但需要GPU,部署成本高。850M参数的方案精度好,但推理延迟接近200ms,同样需要GPU。8M参数的轻量方案能跑在CPU上,但F1只有70%出头,生产环境不可用。
而且,这些方案几乎都只解决"说完vs没说完"的二分类问题,对非语义声音(咳嗽、叹气、噪声)没有专门的处理能力——要么当做"说完了"误触发回复,要么依赖前置的ASR转写结果间接判断,链路长且不可控。
如果你想要一个不依赖GPU、精度还能打、同时能拦住噪声的判停方案,目前没有选择。

TurnSense:不用GPU也能打,噪声一条不漏
今天,百融 Baiji Team 开源了 TurnSense——一个47M参数的语音判停模型,直接以语音为输入,在纯CPU环境下跑出了与7B GPU方案持平甚至略超的精度。
它回答一个问题:
用户这段语音,是说完了、没说完、还是无需回复?
三种输出,三种系统行为:
● Complete → 立即响应。用户表达了完整的意图。
● Incomplete → 继续等待。用户还在组织语言,只是停顿了。
● Invalid → 静默忽略。咳嗽、叹气、清嗓子、打哈欠、环境碰撞声……一切不构成对话意图的声音,系统当它不存在。
这个三分类设计不是锦上添花,而是解决了一个工程上的关键痛点。传统方案中,非语义声音要经过VAD → ASR → 文本判断的完整链路才能被过滤(如果能被过滤的话)。TurnSense在语音层就直接拦截,不给下游任何误触发的机会。整条链路的噪声抑制从"末端补救"变成了"源头拦截"。
关于 Invalid 的边界:如果用户说了一声"嗯"作为回应,TurnSense怎么判?判断依据是这段语音是否携带需要AI响应的意图。纯粹的反馈性语气词("嗯"、"啊")在单独出现时归为Invalid,不会触发AI回复。如果"嗯"后面紧跟着内容("嗯,我想问一下……"),VAD会把它作为一整段语音送入,模型会根据整段判断为Incomplete或Complete。
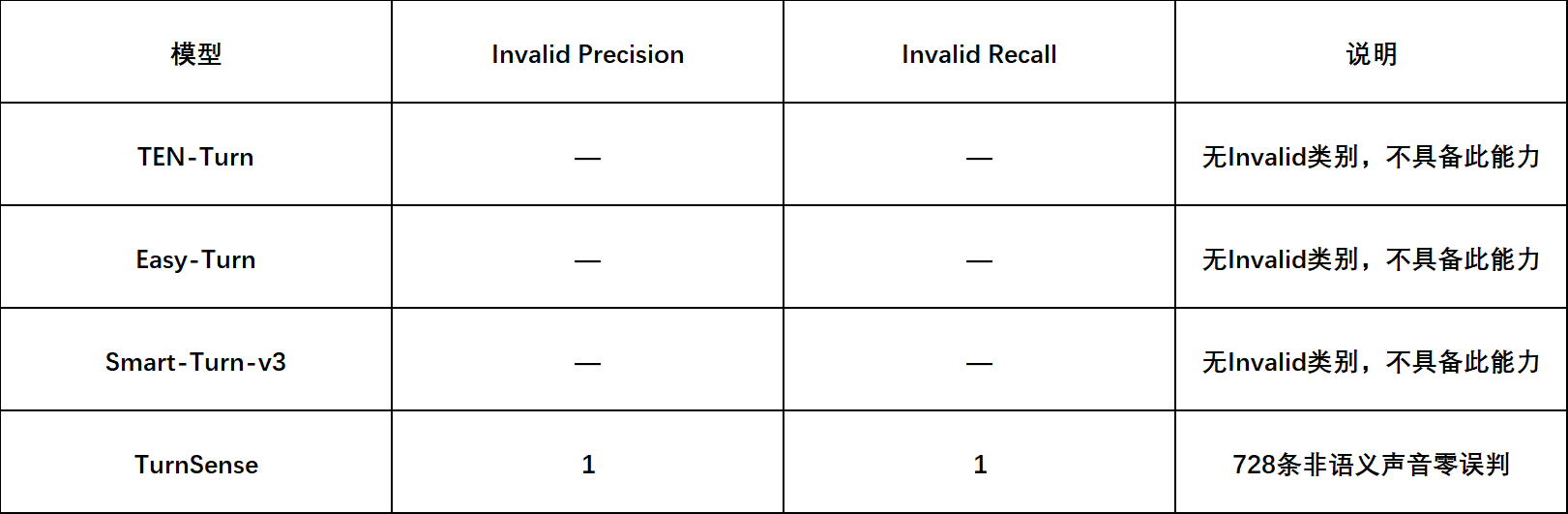
在728条非语义声音测试中,TurnSense做到了Invalid类的precision 100%——咳嗽永远不会触发一次AI回复。零次。

直接看数据
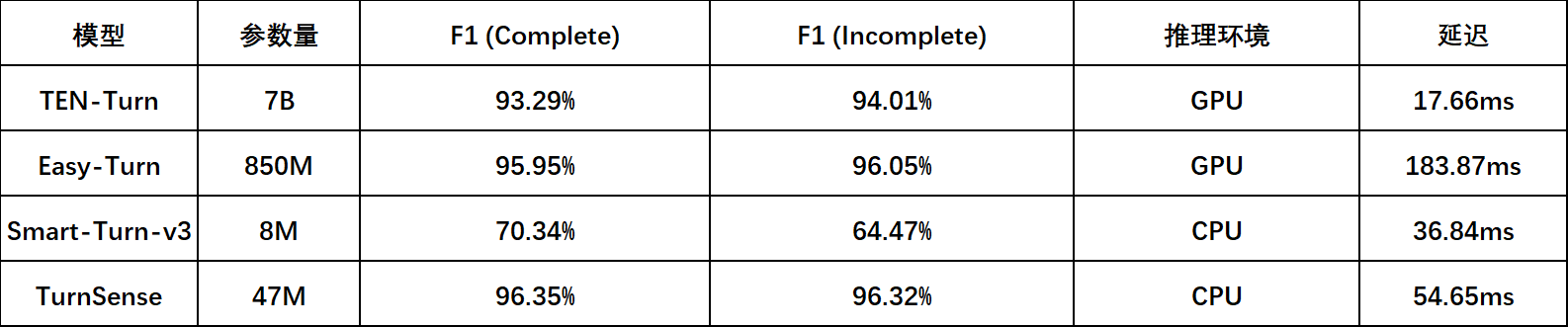
在300条真实中文对话数据(easyturn_real_test_ZH)上的语义判停能力:
在728条非语义声音测试(non_semantic_test)上的噪声拦截能力:
几个值得注意的点:
语义判停方面,TurnSense的F1比Easy-Turn高了约0.3个百分点,比TEN-Turn高了约3个百分点。0.3个点的优势不算碾压,但它是在CPU上跑出来的。 Easy-Turn需要GPU且延迟是TurnSense的3倍多。同等精度下,部署成本差了一个数量级。
噪声拦截方面,其他三个模型根本没有这个能力——它们只做二分类(说完/没说完),遇到咳嗽声只能硬猜一个。TurnSense是目前唯一在模型层面具备非语义声音识别能力的判停方案。
TEN-Turn的延迟确实比TurnSense低(17ms vs 54ms),但它需要一张GPU。如果你有充足的GPU预算且并发量不高,TEN-Turn是合理选择。但如果你需要部署在端侧、需要支撑高并发、或者不想为判停单独买GPU——TurnSense是目前唯一精度达到生产标准的纯CPU方案。

为什么47M能打赢7B?
判停是一个极窄的任务——输入是一段几秒的语音,输出是三选一的分类。它不需要世界知识,不需要长链推理,不需要理解上下文。用7B模型做这件事,就像开卡车去送一封信,99%的运力是浪费的。
但"小模型做窄任务"不是新思路,Smart-Turn也只有8M,为什么F1只有70%?差距在哪?
两个方面。
第一是训练数据。 TurnSense使用了大规模中英文真实对话语音作为训练数据,覆盖了口语中大量的犹豫、停顿、重复、自我修正等现象。同时,训练集中包含了大量真实环境录制的非语义声音样本——各种咳嗽、叹气、环境噪声、设备杂音——让模型学会了区分"人在说话"和"只是有声音"。Smart-Turn的训练数据以朗读式语音为主,遇到真实口语场景和噪声环境泛化能力不足。
第二是模型容量的甜点。 8M太小,无法充分编码语音中的韵律模式和语义完整性特征。7B太大,大量参数被浪费在这个任务用不到的能力上。47M是团队经过多轮实验找到的平衡点——足够大到覆盖判停所需的全部信号(包括区分语义内容和非语义噪声的能力),又足够小到每个参数都在干活。
这不是一个靠灵感找到的魔法数字,是几十次对照实验的结果。
快速使用
接入路径: VAD检测到语音段结束 → 提取音频特征 → 送入TurnSense → 根据结果决定响应/等待/忽略。
注意这里和传统链路的关键区别:传统方案中,所有经过VAD的音频都会送入ASR,ASR的幻觉文本可能触发下游误响应。接入TurnSense后,Invalid的音频直接被丢弃,根本不会进入ASR环节,从源头切断噪声误触发链路,同时节省了ASR的算力开销。
因为TurnSense直接处理语音,它和ASR是并行关系。你可以在TurnSense做判停的同时让ASR开始转写,两者同时跑。TurnSense返回"Complete"时,ASR大概率也出结果了,整体响应延迟取两者最大值而非累加。TurnSense返回"Invalid"时,直接丢弃ASR结果,不浪费下游算力。
模型以标准ONNX格式提供(FP32 / INT8),不绑定任何训练框架。Python、C++、Java、Rust——你的技术栈是什么就用什么。INT8版本约50MB,一台普通云服务器就能跑生产流量,也能打包进车机、手机、IoT设备。
从git clone到第一个推理结果,3分钟:
git clone https://github.com/Bairong-Xdynamics/TurnSense.git
cd TurnSense
pip install -U numpy onnxruntime torch librosa soundfile pandas scikit-learn huggingface_hub
首次运行自动从Hugging Face下载模型。
git lfs install
git clone https://huggingface.co/brgroup/TurnSense
推理
python infer.py
实际效果
我们将TurnSense接入一个开源语音Agent框架做了内部初步测试(100轮对话,涵盖闲聊、任务指令、多轮问答三类场景,测试环境包含正常室内和模拟车载噪声):
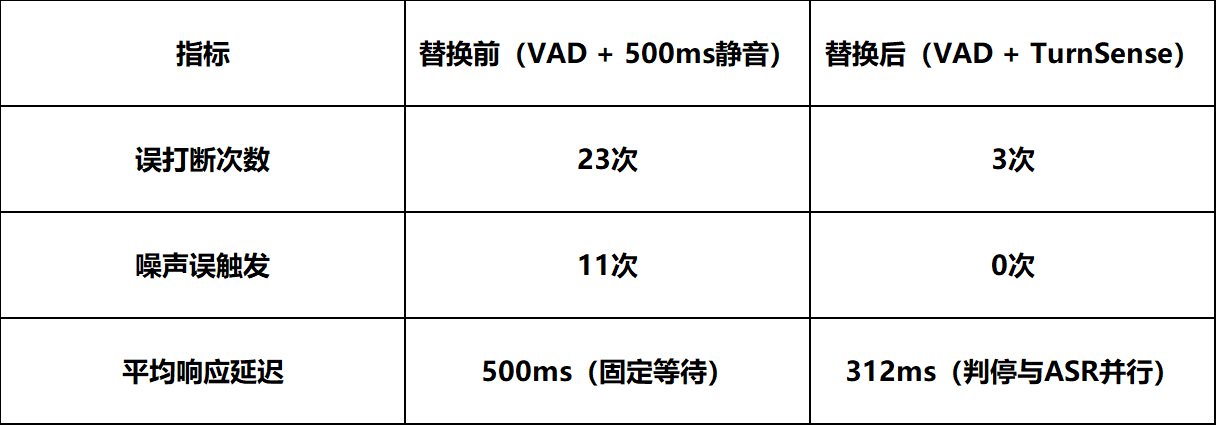
样本量不大,仅供参考方向性趋势,后续会放出更大规模的评测报告。但三个方向性的结论应该是稳的:误打断大幅减少;噪声误触发从11次降到0次,Invalid拦截能力在工程上验证了实验室指标;因为不再需要固定等500ms静音窗口,判停与ASR并行后实际响应反而更快。
噪声误触发归零这一点对特定场景的意义尤为突出:车载场景中路噪和乘客对话频繁;智能客服场景中用户的叹气和清嗓子是高频事件;智能音箱场景中电视声、孩子玩闹声随时存在。这些场景下,一次误触发就可能打断用户体验。
它不能做什么
不处理多轮上下文。 TurnSense只看当前这一段语音,不参考对话历史。大多数场景下单段音频的韵律和内容信息已经足够判断,但确实存在需要结合上下文才能判断的边界case。
中英文为主。 当前训练数据和评测以中英文为主,其他语种的效果尚未充分验证。
不替代VAD。 TurnSense是语义层判停,仍需前置的VAD做语音端点检测。VAD告诉你"这段声音停了",TurnSense告诉你"这段话说完了没"以及"这段声音是不是话"。
音频质量有下限。 极端噪声环境或严重失真的音频可能影响判断。正常通话质量和设备录音没问题。
关于百融 Baiji Team
百融Baiji Team 专注语音交互基础设施,让语音Agent在真实环境中真正好用。核心成员来自国内头部语音AI公司,有多年对话系统工程与研究经验。TurnSense是团队的首个开源项目,后续还会在语音交互的其他关键模块持续输出。
链接
● GitHub:https://github.com/Bairong-Xdynamics/TurnSense
● Hugging Face:https://huggingface.co/brgroup/TurnSense
● 许可证:Apache License 2.0
● 评测框架和数据均随代码开源,支持一键复现所有指标
● 问题反馈和讨论:GitHub Issues / Discussions
Apache 2.0,商用免费。用了觉得好,GitHub给个star;用了遇到问题,提个issue,我们会跟。
关键词:
相关阅读
-
施罗德投资:地缘政局虽添变量,但盈利增长护航下继续看好股票前景
施罗德投资多元资产投资团队尽管近几周地缘政治阴霾笼罩各地,但施罗德投资维持看好股票的策略已获证明是正确之举事实上,早在3月份能源价格飙升时,施罗德投资已就整体商... -
微软纳德拉官宣MDASH框架,协调100+模型AI抓虫-热门
微软纳德拉官宣MDASH框架,协调100+模型AI抓虫,dll,sys,安全漏洞,知名企业,mdash,微软纳德拉官宣 -
腾讯元宝:新增一键总结微信群聊等功能
5月13日,腾讯发文称,微信群聊能一键总结了,选中微信群聊聊天记录转发其他应用-选择元宝-复制粘贴给元宝,就能自动梳理核心重点。 -
广州俊恺电子科技有限公司成立 注册资本50万人民币
天眼查App显示,近日,广州俊恺电子科技有限公司成立,注册资本50万人民币,经营范围为电力电子元器件销售;电子测量仪器销售;电子元器件与机电组件设备销售;电子真 -
最资讯丨李彦宏:智能体出圈代表着AI的发展从模型转向了执行力
李彦宏:智能体出圈代表着AI的发展从模型转向了执行力,出圈,李彦宏,智能体 -
热推荐:西北省间电力互济交易启动模拟试运行
科技日报讯(记者王禹涵通讯员高敏)记者5月11日从国家电网有限公司西北分部获悉,西北区域省间电力互济交易日前正式启动模拟试运行。这是西北地区首次实现从省间辅 -
47M参数打赢7B:语音判停模型TurnSense开源
你的语音Agent又抢话了用户说"我想订那个……就是上次去过的那家……",话还没说完,AI已经兴冲冲回了... -
快报:76人解雇总经理莫雷 六年任期无冠告终
76人解雇总经理莫雷六年任期无冠告终,恩比德,火箭队,76人队,莫雷(心理学家) -
航天领域重大资产重组!今天起复牌,股价曾提前涨停|今头条
航天领域重大资产重组!今天起复牌,股价曾提前涨停 -
【热闻】C罗首冠延后!利雅得胜利遭绝平1-1新月 仍5分领跑 门将压哨送礼
C罗首冠延后!利雅得胜利遭绝平1-1新月仍5分领跑门将压哨送礼,c罗,科曼,萨里,利雅得,本泽马,米林科维奇,布罗佐维奇 -
焦点速看:亚洲最大城中湖环湖绿道雏形初现 汤逊湖绿道一期今年底建成迎客
5月9日,鸟瞰亚洲最大城中湖武汉汤逊湖环湖绿道一期工程,目前,一期部分路段已建成,预计今年底建成迎客。该工程位于江夏区科技工作者社区核心范围,北起羊子山街、南至 -
盛合晶微多层细线宽系统集成封测项目(一期)在江阴奠基
人民财讯5月12日电,5月12日,盛合晶微半导体有限公司(简称“盛合晶微”)多层细线宽系统集成封测项目(一期)奠基仪式在江阴高新区举办。 -
光学概念股排名前十(2026/3/25)
光学概念股有工业富联、立讯精密、海康威视、蓝思科技、豪威集团、歌尔股份、高德红外、大华股份、菲利华、光库科技等65家上市公司。概念库为您整理光学概念股的详细介绍。内 -
媒体人:今晚京粤大战,广东队给球员开出200万赢球奖 每日快看
媒体人:今晚京粤大战,广东队给球员开出200万赢球奖,八强,广东队,cba,生死战,京粤大战 -
今日热议:5月12日生意社豆粕市场基差为-63元/吨
发布时间:2026年05月12日18:11,生意社发布5月12日生意社豆粕市场基差为-63元/吨 -
快资讯丨30股股东户数连降 筹码持续集中
投资者可以在交易所互动平台上通过提问方式了解部分公司更及时(每月10日、20日、月末)的股东户数信息。 -
ETF主力榜 | 科创债ETF嘉实(159600)主力资金净流出33.23亿元,居全市场前3-20260512
2026年5月12日,科创债ETF嘉实(159600.SZ)收涨0.02%,主力资金(单笔成交额100万元以上)净流出33.23亿元,居全市场前3。(数据来源:Wind)与此同时,该基金最新成交量为5 -
行业洗牌进入深水区,云迹科技靠“智能体即服务”拿下百亿级资本的信任票
近期,随着人形机器人赛道的持续升温,资本市场对机器人板块的关注度达到了空前高度然而,在资本狂热追逐“未来概念”的同时,理性的长线资金正在... -
曼丹达谈退役:我觉得自己活得并不快乐,整个人茫然迷失
曼丹达谈退役:我觉得自己活得并不快乐,整个人茫然迷失,迷失,快乐,国门,曼丹达 -
一场112:103赛后!哈登打服黑粉,米切尔道歉,双塔说了句实话
一场112:103赛后!哈登打服黑粉,米切尔道歉,双塔说了句实话,双塔,阿伦,莫布里,汤姆·米切尔,詹姆斯·哈登